
Deep learning is a sub-field of artificial intelligence that combines feature engineering and classification in one method. It is a data-driven technique that optimises a predictive model via learning from a large dataset. Digitisation in industry has included acquisition and storage of a variety of large datasets for interpretation and decision making. This has led to the adoption of deep learning in different industries, such as transportation, manufacturing, medicine and agriculture. However, in the mining industry, the adoption and development of new technologies, including deep learning methods, has not progressed at the same rate as in other industries. Nevertheless, in the past 5 years, applications of deep learning have been increasing in the mining research space. Deep learning has been implemented to solve a variety of problems related to mine exploration, ore and metal extraction and reclamation processes. The increased automation adoption in mining provides an avenue for wider application of deep learning as an element within a mine automation framework. This work provides a compact, comprehensive review of deep learning implementations in mining-related applications. The trends of these implementations in terms of years, venues, deep learning network types, tasks and general implementation, categorised by the value chain operations of exploration, extraction and reclamation are outlined. The review enables shortcomings regarding progress within the research context to be highlighted such as the proprietary nature of data, small datasets (tens to thousands of data points) limited to single operations with unique geology, mine design and equipment, lack of large scale publicly available mining related datasets and limited sensor types leading to the majority of applications being image-based analysis. Gaps identified for future research and application includes the usage of a wider range of sensor data, improved understanding of the outputs by mining practitioners, adversarial testing of the deep learning models, development of public datasets covering the extensive range of conditions experienced in mines.

Avoid common mistakes on your manuscript.
Advances in digitisation in industries has led to a big data revolution that has provided opportunities for improving performance in many tasks through data-driven methods for reasoning, modelling, optimisation and decision making (Thomas and McSharry 2015). In the mining industry, the extensive use of sensors and instrumentation has enabled large amounts of data to be collected in real-time from machinery during daily mine operations. These data appear in different forms (e.g. images, point clouds, discrete, time series) and dimensions (e.g. from 1D to 4D/5D and more) which have the potential to be indexed and fused into combined problem space representations. The large amount of collected data provides opportunities to be exploited through artificial intelligence (AI) methods, focusing on data-driven methods such as machine learning (ML) with its sub-fields including deep learning, with the aim of finding correlations, clusters and categories for gaining insights for improving both the safety and the productivity of a mine site (RioTinto 2022).
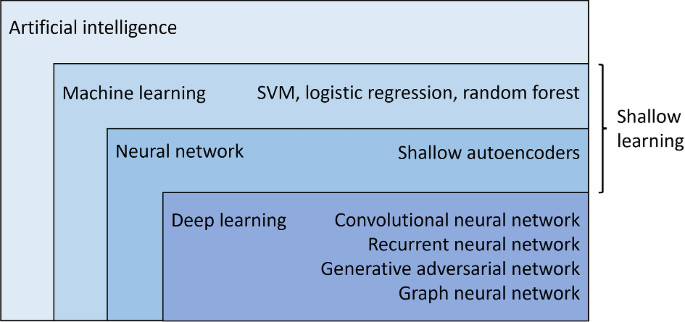
The theoretical definition and technical details of deep learning (DL) is well explained in a number of reference either comprehensively (Lecun et al. 2015; Goodfellow et al. 2016; Chollet 2021) or succinctly as a section of a review (Méndez et al. 2023; Zhang et al. 2021). This section aims to engage potential mining audience by giving a high-level explanation to DL. As depicted in Fig. 1, artificial intelligence (AI) encapsulates a range of developing technologies. Machine learning (ML) is capable of performing data classification and regression. Artificial neural network (ANN) is a subfield of ML that use layers of neurons with weightings that are trained to represent the transformation of the data into an output. DL consists of multiple layers of neurons derived from ANN capable of feature extraction and improved prediction.
In DL methods, the primary data structure is a network of nodes connected by links (also known as a network configuration (Pingel 2022)), where each node has a set of input links, providing inputs from data inputs or the outputs of other nodes, and output links connecting to other nodes or network outputs (Lecun et al. 2015). A node mimics a simplified model of a biological neural network. Historically, this has been an integrate and fire model, where a neuron is modelled as an integrator that sums the input values and generates an output if the sum exceeds a threshold (Burkitt 2006). A DL is a method that derives rules from data for mapping input data to desired outputs and is trained (in the case of supervised learning) using an algorithm that uses the error between the outputs generated by the DL model from specific examples of inputs and the ground truth outputs provided by the training data to modify the weights and biases within the network, aiming to optimise the overall performance (e.g. accuracy and precision). When a target level of performance is reached, the training process can end and the resulting DL model can function on new data sets to automate the classification of their data vectors.
The experimental performance of a DL is typically assessed by separating (e.g. randomly) the data into training set, validation set and test set. The DL learns or extracts features (i.e. weights and biases) from the training set. The validation set is used to compare the model’s performance during training at certain intervals and is not used to optimise the model’s parameters. At the end of the training routine, the model is then tested by applying it to the known correct categories for a given input vector in the test set. The practice of data separation aims to ensure the validity of a trained model during and after training and to identify the model’s generalisation biases at different points i.e. overfitting and underfitting as explained in Lei (2021), Wagner et al. (2021) and Jabbar and Khan (2015). The broader question of validity concerns the performance of the DL network when applied beyond the initial training and testing context, i.e. to situations where the constraints and distribution of data inputs encountered may differ or not, in ways that may or may not be known or anticipated, from the data used to develop the DL network.
The term ‘deep’ in deep learning does not refer to the depth of the learning model’s comprehension capability but refers to the number of layers in the network architecture (Chollet 2021; Kavlakoglu 2020), which raises the question: How many layers does a network architecture need to have to be considered a deep learning method? Although there is no general consensus on the definition, in this paper, a network architecture is considered to be ‘deep’ if it consists of at least two hidden layers, a total minimum of 4 layers including the input and output layers (Kavlakoglu 2020).
DL throughout the recent decade has been a focus of attention because of its proven state-of-the-art performance in solving multiple tasks, especially in computer vision thanks to the increasing amount of publicly available datasets and computational resources. DL gained momentum in 2012 when a convolutional neural network (CNN) called AlexNet (Krizhevsky et al. 2012) created by the research team ‘SuperVision’ outperformed all competitors by a significant margin in the ImageNet Large Scale Visual Recognition Challenge (ILSVRC) (Russakovsky et al. 2015). Subsequently DL has been adopted outside the computer vision field in other research domains and industries to solve numerous tasks involving classification and regression. However, the majority of DL adaptations in other application domains have been implemented with minimal architectural modifications. Changes are typically limited to the datasets and network training methodology used.
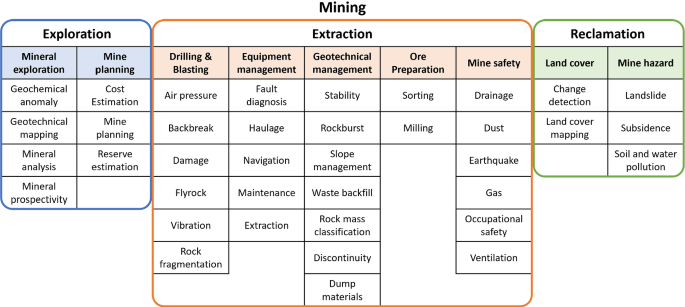
DL implementations have been extensively reviewed for geochemical mapping (Zuo et al. 2019), geosciences (Ayranci et al. 2021), ophthalmology (Wang et al. 2021c; Badar et al. 2020), finance and banking (Huang et al. 2020; Ozbayoglu et al. 2020) and medicine (Liu et al. 2021b; Wang et al. 2021a; Debelee et al. 2020; Bizopoulos and Koutsouris 2019; Bakator and Radosav 2018). However, DL reviews in the mining context, such as by Jung and Choi (2021) and Fu and Aldrich (2020), have not been extensive. The scope of the review by Jung and Choi (2021) includes a broader context of ML with a limited number of DL approaches (only 63 papers were reviewed). Meanwhile, Fu and Aldrich (2020) only include extraction, transportation, and processing of minerals in the mining context, providing a compact overview of DL methods focusing on implementation in these application fields. Other processes in the mining value chain could include exploration, planning, safety and reclamation. This paper aims to provide a comprehensive systematic review of published work on DL implementations in metal and coal mining-related applications, categorised based on the mining tier processes in Fig. 2. The aim is to encourage generalising DL adoption in different mining processes. The literature review aims to answer the following questions:
The first question is answered by examining trends such as the distribution of DL usage and related network architectures categorised across different mining processes. Answers to the second question consider the application context, the problem to solve, network architecture training methods and data. The answer to these questions will be the basis for outlining the limitations of these implementations. As a summary, the gap between state-of-the art deep learning approaches and their adoption in the mining context will be outlined with suggestions for possible implementation frameworks.
The knowledge domain of these applications could also be derived from other domains such as geotechnics, geoscience, remote sensing, computer vision and robotics because mining is an interdisciplinary field which includes a wide variety of processes. The included relevant literature in this survey is motivated by mining applications and/or applied to data collected from a mine site and not those that might have a potential to be applied in a mining context. To avoid redundancy, this paper excludes DL approaches in mine operations that have been compiled which include blast-induced impacts (Al-Bakri and Sazid 2021), blast vibration (Maulana et al. 2021) and microseismic event classification (Jinqiang et al. 2021).
The mining industry could benefit from adopting DL method compared to ML techniques and analytical/numerical modelling in several different ways: (a) The large amount of data collected in the mining process could be exploited to make prediction and analysis for increase efficiency and productivity given DL is a data driven method. (b) DL methods do not require feature engineering and extraction which would require minimal data processing in comparison to ML techniques. (c) In comparison to analytical or numeral modelling, DL methods would require less mining expert intervention in the process of developing the model. (d) Finally, DL methods would take less time to make inferences given a trained model in comparison to numerical or analytical methods.
The articles collated are categorised based on the main processing involved i.e. exploration, extraction and reclamation and breaking it down based on the hierarchy as depicted in Fig. 2. The rest of the paper is structured as follows. Section 2 explains the search methodology used to find relevant articles. Section 3 outlines the trends of the published articles based on publication year, DL architecture and mine processes involved. Section 4 discusses the DL implementation in the articles categories into subsections based on the 3 main processes followed by Sect. 5, which discusses the findings, recommendations, and future prospects. Finally, the conclusion outlined in Sect. 6.
Using research databases such as Google Scholar, Web of Science, Scopus, Springer, ScienceDirect and IEEE Xplore to find relevant deep learning literature, mining processes keywords such as ‘Exploration’, ‘Extraction’ and ‘Reclamation’ were used in combination with their sub-keywords as shown in Fig. 2. These keywords were combined by adding ‘deep learning’ keywords and its specific method terms such as deep learning (DL), artificial neural network (ANN), fully connected network (FCN), convolutional neural network (CNN), generative adversarial network (GAN), recurrent neural network (RNN) and other derived networks to create an initial list of publications.
A second search session was conducted by including distinct relevant literature from the list of references and cited papers of the initial list. The literature searches were repeated until the references were exhausted, i.e. when the relevant articles from the references and cited papers in the respective articles in the collated publication list had been included.
The collated publication list was then filtered by skimming each article, ensuring their relevance within the scope of this paper by reading through the abstract, introduction, methodology (focusing on the network used) and its data. As mentioned in the introduction, only articles that matched the following criteria were included in the final review list, which comprised 111 articles: (a) Motivated and/or applied in a mining context; (b) Using a network consisting of a minimum of two hidden layers; and, (c) Not including the mining context of blast-induced impacts, blast vibration and microseismic event classification.
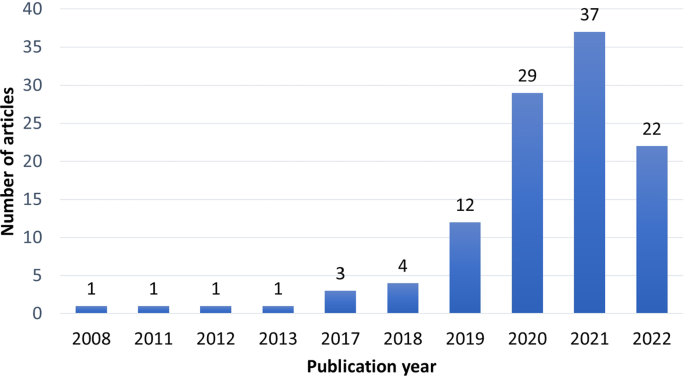
A total of 111 articles were included for review in this survey. To examine the trends, Fig. 3 shows the distribution of articles according to their publication year. The number of deep learning articles in the mining context increased exponentially with 37 articles in 2021. Acknowledging the fact that the publications included were only up to the first quarter of 2022, the projected publication number in the year 2022 would likely more than double the previous year assuming about the same amount of work to be published each quarter. The implementation of ANNs in the mining context can be traced back to 1995 (Maxwell et al. 1995), where an ANN was used to predict the size of materials on a conveyor belt for mineral processing. The limited processing resources and data available then restricted the number of layers included in the neural network to one hidden layer. This one-layer implementation not only requires fewer resources but also reduces the capacity to overfit the machine learning model due to the small amount of data used, however, this does not satisfy the deep learning definition in terms of the minimum number of layers required. An analysis of articles based on the publication venue is provided in the associated supplementary information.
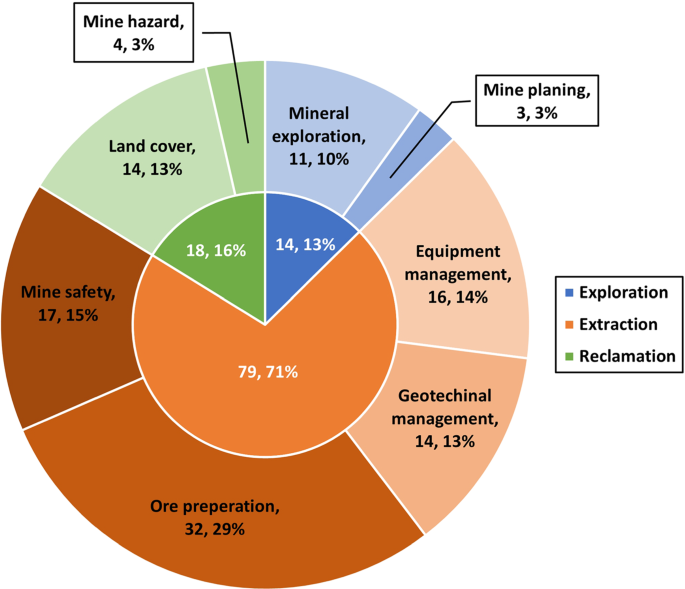
Figure 4 shows the distribution of published articles in each respective mining process. As shown in Fig. 4, the majority of articles were published covering the topic of minerals extraction, which accounts for about 72% of the total articles collated. The rest of the collated articles covered exploration and reclamation processes, with 31 published articles in total. The large number of articles focusing on the extraction method could be due to many reasons, although it is notable that extraction represents the primary capital investment in mining. In addition, the number of extraction sub-processes included in the review is twice as many as the number of sub-processes of the other processes individually. Also, some of the sub-processes, for example, mineral exploration and land cover, can be generalised into the geoscience and remote sensing field, respectively, where the context of application and motivation are not restricted to mining. However, only the articles that were applied specifically in the mining context were included in this review.
Figure 5 shows how the distribution of DL network types were broken down with respect to the three main mining processes. As shown in Fig. 5, the majority of DL implementations adapted a CNN approach which accounted for 78 articles, more than 70% of the published articles reviewed. FCN which is the basic implementation of an ANN, accounts for a total of 17 articles, about 15% of the total reviewed articles. RNN which is a DL architecture suitable for time-series or sequential data, accounts for a total of 13 articles. 2 articles were published implementing 3D convolutional neural network (3D-CNN) which is a type of CNN capable of performing convolution on unorganised volumetric data such as point clouds. Finally, one article reported implementing a deep belief network (DBN), which is a specific type of DL network that employs a greedy learning method for optimisation rather than the back propagation method used in the other network types included in this review.
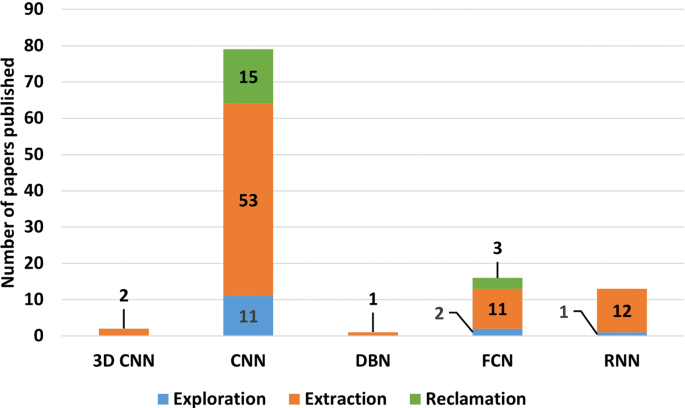
The emphasis on CNN probably arises because it is a DL technique commonly applied for image-based tasks such as object identification and segmentation. This is the type of network that was made popular due to the state-of-the-art performance achieved in the ILSVRC challenge as mentioned in the introduction. Since then, most development has focused on CNN architecture compared to other types of DL networks. As a result, many simplified libraries and trained models were made easily accessible for a number of well known CNN implementations such U-Net (Ronneberger et al. 2015) and Mask R-CNN (He et al. 2017). The availability of a large image dataset and the cheap cost of image-based sensors in combination with the development of CNN as described are the possible driving factors for its adoption in the mining context.
This section provides a review of deep learning implementations in the mining context, categorised based on the three main processes: exploration, extraction and reclamation. This review aims to establish existing knowledge of how DL methods have been adapted for solving problems in mining, in order to identify the gaps in the research conducted to date.
Tables 1, 2, 3, 4, 5 and 6 in the following sub-sections show the publications reviewed for each category of mining processes with the general network type used and applications. These applications briefly answer the question: ‘What type of problem does the DL implementation focus on solving?’ and considers only the component in the problem space for which DL was implemented. For example, DL is used by Wang et al. (2020) (Table 6) to segment the mine site area given a single satellite image with the aim of automating monitoring of land usage changes within a given period. However, the proposed change monitoring component does not adopt a DL technique, hence the change monitoring method is not mentioned in the ‘Specific application’ column. The ‘Specific application’ column also highlights the dataset used in each study with regards to their sources, contents, acquisition techniques and amount.
DL has been used to solve a variety of problem in domains that require different forms of outputs. In the ‘Specific application’ column of Tables 1, 2, 3, 4, 5 and 6 the terms ‘estimating’, ‘classifying’, ‘detecting’, and ‘semantic segmenting’ are used to describe the DL task when solving a particular problem. These tasks are defined as follows:
A DL approach could perform multiple tasks such as performing detection, classification and semantic segmentation using a single model. An example in a hyperspectral image is to draw a bounding box (i.e. detection), classify the mineral group of the bound box sub-image (i.e. classification), and then classify all the pixels in the bounding box belonging to the classified mineral type rather than the background (i.e. semantic segmentation) (Galdames et al. 2022). The text in the following sections also includes further discussion of selected implementations and their results as a guide for future studies.
Exploration is the initial process in the mining value chain. During exploration, activities such as mapping, and mineral analysis and prospecting are carried out to estimate the mineral location and reserve size. This information is then used for mine planning and cost estimation to identify a feasible operating approach to gain investment to proceed with setting up the facilities to extract the economically feasible minerals.
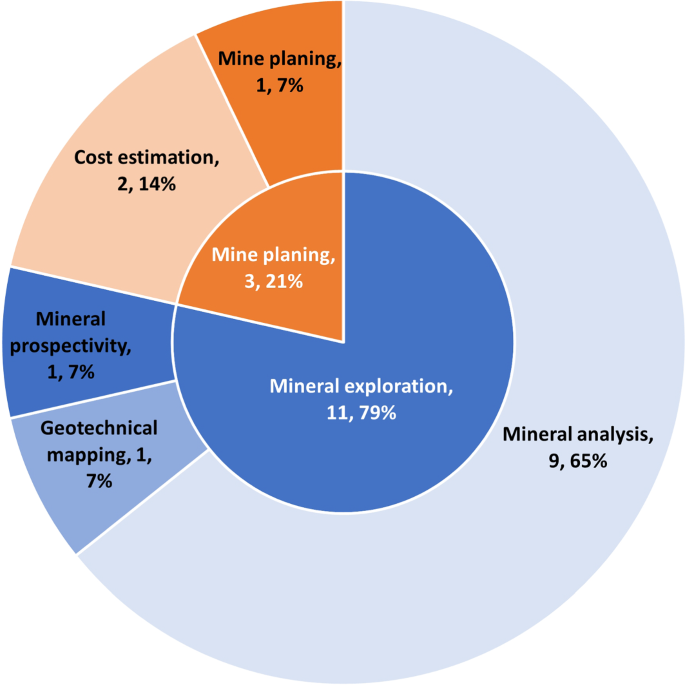
Figure 6 shows the distribution of mining processes involved in the mine exploration phase and Table 1 outlines the specific DL application applied in each article. These processes are categorised into two: (a) Mineral exploration, the process of mapping the geology, predicting mineral types and amount; and (b) Mine planning, the process of planning and estimating cost for mine operations. As mentioned earlier, mining-related exploration articles only accounted for about 13% of the overall articles reviewed. This could be due to the broader research field these processes belong to such as earth sciences and geology, wherein mining is an applied subfield.
Referring to the distribution in Fig. 6, the majority of articles reviewed involved mineral analysis, which accounts for 9 articles, about 65% of the total articles reviewed in mine exploration. These articles focused on identifying different types of rocks and minerals in images obtained from different types of imaging sensors as input utilising a CNN as listed in Table 1. Li et al. (2022b) proposed a simplified and lightweight network based on YOLOv3 by experimentally removing unneeded layers and branches. The dataset used was augmented to increase the number of training data which was also implemented by Liang et al. (2021) and Asiedu et al. (2020). A siamese adversarial-based network was proposed by Hao et al. (2022) which takes in the same microscopic image polarised differently to classify the type of minerals and their origin in one single architecture based on ResNet (He et al. 2016). The proposed network performance by Hao et al. (2022) and Filippo et al. (2021) was cross-validated by testing the trained networks with a dataset from a different context to the one used for training. Ran et al. (2019) proposed an image cropping method as the input layer and performed scoring by voting for the output confidence scores of the cropped images from the same single image to identify the rock type of the un-cropped image. Jin et al. (2022) proposed a network that uses U-Net (Ronneberger et al. 2015) as the backbone incorporating inception blocks (Szegedy et al. 2015) and dense connection blocks (Huang et al. 2017) as layers which achieved a pixel-wise accuracy of 93%, similar to its predecessor i.e. U-Net, ResNet and SegNet (Badrinarayanan et al. 2017), but was capable of converging faster as well as maintaining its performance across the training epochs without any fluctuations during validation. Baraboshkin et al. (2020) compared the lithography classification performance of AlexNet, VGG (Simonyan and Zisserman 2015), GoogleNet (Szegedy et al. 2015) and ResNet whereby all the network achieved similar f1 scores ranging from 93% (ResNet) to 96% (VGG). This shows the maturity of image-based DL methods whereby the network choice should be based on other aspect such as amount of data needed and computational time rather than their raw classification performance.
The article published relating to geotechnical mapping utilised RNN based on a long short-term memory (LSTM) network that takes into account well log neighbourhood layers for sedimentary facies classification (Santos et al. 2022). The proposed network outperformed traditional ML techniques such as XGBoost, random forest, naive Bayes and support vector machine (SVM) in terms of classification performance of a geological layer is depending on its neighbouring layers within the same borehole and layers from neighbouring boreholes.
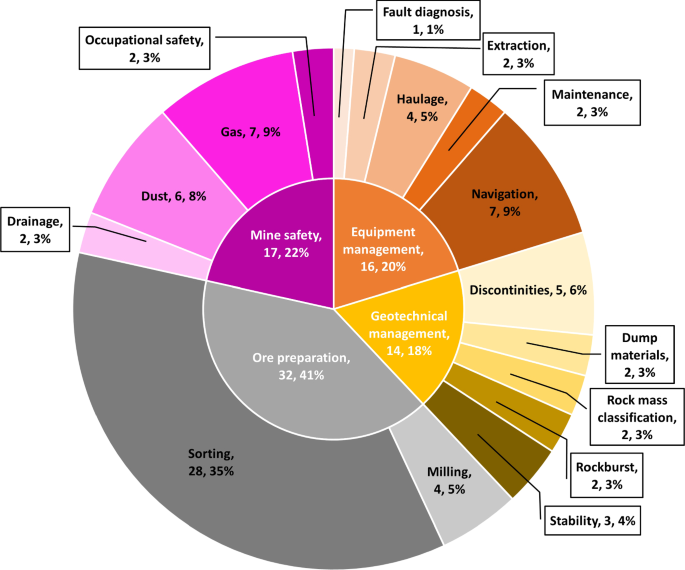
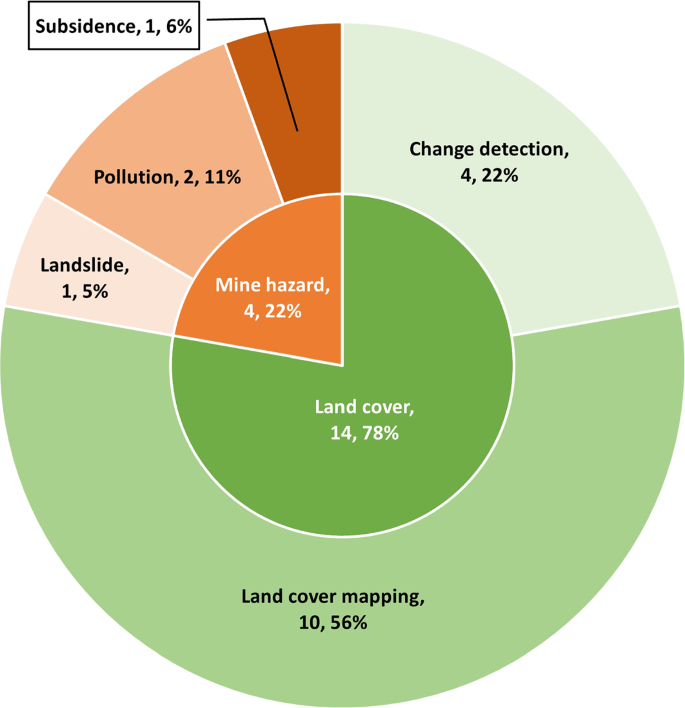
Figure 8 shows the distribution of mining processes involved in the mine reclamation phase and Table 6 outlines the specific DL application applied in each article. Reclamation processes are categorised into two: (a) Land cover, the process of mapping the change in mine land usage; and (b) Mine hazard, the process of monitoring and preventing mine hazards that could have an effect on the environment. Overall, DL-based mine reclamation articles account for about 16% of the total DL in mining articles reviewed in this survey. Out of all the reclamation articles, the majority, i.e. 15 articles, implemented a CNN which takes in images either from a camera or derived from other sensors such as LiDAR and satellite images. The rest, i.e. 3 articles, implemented an FCN to perform classification or estimation using 1D mine data.
Referring to the DL articles in mine reclamation distribution in Fig. 8, 4 articles were published relating to change detection which accounted for about 22%. Even though the research is focused on detecting changes in land usage, only one article uses a DL technique to segment out the differences in land change over time (Tang et al. 2021). This is achieved with a Siamese CNN which takes in two images as input i.e. images of the same area from different time frames and outputs the differences in land use between the two time frames. Meanwhile, the rest of the change detection articles used DL as a tool to segment different types of land use from an image of the same area taken over a period of time. A non-DL-based technique is then applied to the segmentation output comparing the area differences over the period. Wang et al. (2020) implemented a Mask R-CNN which is a DL network that outputs bounding boxes surrounding the region around the object of interest and segments the pixels within the bounding box representing the object. This method provides better classification performance compared to a network that is purposely designed for semantic segmentation such as U-Net. Mask R-CNN restricts the region in the image for semantic segmentation to regions of high confidence where the objects of interest are localised.
Table 6 Description of articles surveyed in mine reclamation processesThe majority of mine reclamation articles reviewed are related to land cover mapping, which accounts for 10 articles, about 56% of all reclamation articles reviewed. Malik et al. (2021) used a multi-input approach by combining image and surface models derived from UAV imagery. For a DL network that takes in multiple inputs rasterised as an image layer, Chen et al. (2020) proposed a feature input reduction method to filter and keep input data that contributes to the performance of the network. Yan et al. (2021) applied transfer learning during model training using weight and biases from the same model trained using a different image dataset, ImageNet. Other than transfer learning, data augmentation can also be used to increase the number of datasets for training, for example, Xie et al. (2021) flipped and rotated the training images in different ways to increase the number of training images and randomly changed the luminance and colour space of these images to simulate images taken in different seasons and lighting conditions. These generated images were then used to trained a hybrid DL architecture based on U-Net and SegNet which during testing achieved a pixel-wise f1 score of 67% compared to 63% and 65% from U-Net and SegNet, respectively.
Ji and Luo (2021) proposed an ensemble learning methodology based on CNN to perform semantic segmentation of different land types in a multispectral image. The proposed method was then compared to other DL and machine learning methods whereby proposed ensemble method achieved a pixel-wise accuracy of 94% compared to 87%, 83%, 76% and 72% of those from the base CNN, ANN, extreme learning machine (ELM) and SVM, respectively.
The rest of the published mine reclamation articles related to mine hazards, which accounts for 4 articles, about 22% of the reclamation articles reviewed. Among these articles, Luo et al. (2019) performed feature filtering for the input data and a k-fold validation process.
The implementation of DL methods in the mining research context has grown exponentially since 2017, as shown in Fig. 3. This adoption is most likely driven by the maturity of DL algorithms, which have rapidly advanced since the outstanding achievement of AlexNet (Krizhevsky et al. 2012) in 2012 and the success of DL implementations in other industries. Additionally, the availability of large datasets in combination with capable computing resources enables rapid implementations of DL in the mining research context, enabling the kinds of implementations and trials documented in this paper as a basis for better understanding the potential economic impacts of DL applied in mining. The aim of the study was to provide a generalised and compact comprehensive review of DL implementation in the mining industry. The review outlines the general type of network used in each study including the tasks that the respective DL methods were aimed to solve. The specifics of the network designs and datasets used have not been detailed since they have been applied to different cases that might not work for or generalise to other cases.
The review has shown that firstly, the trend of DL adoptions in the mining context shows an exponential increase and secondly, there are wide range of different situations across the exploration, extraction and reclamation process for which DL methods were implemented and that the reason for applying deep learning are estimation, classification and, to a lesser extent, semantic segmentation. It is important to discuss some of the learnings from the review in term of the range of methods applied, the availability of data and the challenges that the mining environment created for the implementations.
The majority (70%) of the articles included in this review implemented a CNN method. This could be due to the maturity of this type of network following its rapid improvement post-AlexNet. The affordability of high-quality image-based sensors and their ease of deployment drive the availability of large mining datasets for developing the DL model. CNN is widely used in the included articles such that other forms of data such as point clouds, geological data and hyperspectral spectrum are rasterised into images to be used as the CNN input. The conversion of data types from these sensing technologies could cause the loss of rich information captured from the complexity of a mine environment.
While CNNs have been proven to work effectively on images, it is not necessarily confirmed that they would be as effective on other data types converted to images. The conversion itself could cause loss of valuable information. As an example, an FCN could be used for image classification tasks by flattening 2D image pixel matrices into 1D vectors. Such an FCN implementation for image classification could produce good results but was more effective when using a CNN. Similarly with point cloud processing where point clouds were converted or projected into images and other forms of point cloud projection prior to the proposal of PointNet (Charles et al. 2017). This showed that selecting the correct DL approach for the data types is vital. Hence, it might be worth developing new architectures for different data types rather than just relying on data conversion to fit the input requirements of a particular network type.
Apart from CNN, the other type of networks adopted in the mining literature are FCN, RNN, DBN and 3D-CNN. A wider range of techniques, such as GAN and graph neural network (GNN) and transformers should be considered for performing tasks such as image classification and detection, air particle estimation, point cloud segmentation, and dust and pollution estimation that can be important to quantify the influence of mines on their environment.
A DL model is a generalised function of a specific task given input data and training the DL algorithm to find the optimal weights and biases that maps the input data to the labelled output. Hence, having the right data for the task is crucial not only for DL but for any AI applications. A common problem of DL mining applications is the limited and poor-quality data that arises from slow adoption of sensor data. The consequences will be over-fitting whereby the model fits the training data well but performs significantly worse during evaluation and applicability to other sites with different geology, design and equipment will be limited.
In comparison with the many thousands or millions of data points in image and financial analysis, the limited number of data points available for mining DL studies shown in Tables 1, 2, 3, 4, 5 and 6 include such small numbers as 305 images with 8 features up to what could bee seen as large in the mining context as 2 mills with 15,905 data points taken only at half hour intervals. Other studies show researcher using Kaggle concrete datsets to simulate rock (Yi et al. 2022). This suggests the opportunity for improved DL focussed data collection in mining and for researchers to work together to combine datasets for more generic results.
In terms of data availability, the majority of the datasets used in the included articles were collected in particular mine sites and were not publicly accessible. A dataset collected from a particular mine site might not be generalisable to the same application in a different mine site, or even at the same mine site over time. This could be due to differences in sensors, sensor setup and environmental conditions, and also changes in the nature and content of excavated material as mining progresses at a site. A number of articles used publicly available datasets obtained from government led projects, organisations and general internet searches. These articles mostly focused on applications that use mapping data. The topological map of mining areas in West Virginia, USA obtain from WVU (2022), USGS (2022a) and USGS (2022b) were used by Maxwell et al. (2020a, 2020b) to classify land usage in mine sites. Similarly, data from Google Earth (Google Earth 2022) and images obtained from satellites such as Sentinel (ESA 2022), Landset (NASA 2022), and Gaofen (CRESDA 2022) were used to obtain RGB and hyperspectral images of a mining areas where the respective satellite covers either a full site (Balaniuk et al. 2020; Tang et al. 2021; Kumar and Gorai 2022; Xie et al. 2021; Meng et al. 2021; Chen et al. 2020) or by combining images from different sources taken of the same area (Malik et al. 2021; Luo et al. 2019; Wang et al. 2020). Even though these satellite datasets are publicly available, the proposed methods were not cross-validated with images of different mine sites. Similarly, well logs from Rio Bonito, Brazil collected by the SGB (2022) were used to classify different types of facies by Santos et al. (2022) and should be tested against data from other countries. Images of different rock types collected from general search engines were used to train a rock type classifier (Asiedu et al. 2020), however, the collected images were not detailed or published for replication.
Despite the limited publicly available data, organisations such as Humyn.ai (Humyn 2022) have been organising data science challenges to solve proprietary mining and resources-related problems proposed by mining companies. However, these challenge outcomes remain confidential and cover a wide range of disciplines, which includes data mining (analysis of large datasets to extract patterns), giving talks as well as machine learning.
Apart from publicly accessible datasets, an open access to the code written associated with the published articles provides a detailed technical implementation which might not be sufficient with the high-level ideas and methodology presented in a research article. Appending source code to a published article should be encouraged as a part of submission requirements such as currently practised in Computers and Geosciences (Jin et al. 2022; Hao et al. 2022; Liu et al. 2021d; Xu et al. 2021).
A general question to ask is whether a deep learning method developed in a research or prototyping context is suitable to be deployed in the industrial context. Two factors for consideration includes the model’s suitability in the deployment environment as well as the feasibility of adopting such technology, e.g., cost benefit analysis. Deep learning is a data driven method where the model produced is optimised for the particular dataset used during model development. A model should perform comparatively well in the operational environment if the model was well fitted to the training dataset used to develop it, i.e., in terms of noise and systematic variations. However, including the same noise and variance as expected in the output can be difficult in an environment where the geology and operational processes are varying continuously in space and time. This is a general challenge for a priori learning of models that are intended to be applied in dynamic environments. This will require further evaluation in terms of the contextual similarities between the experiment and the deployment in the mining environment and would benefit from conducting a sensitivity analysis and more testing in different, real environments than is often indicated in the papers. Potential methods for addressing this challenge include the development and application of methods for characterising operational dynamism, the integration of prediction in learning methods and their resulting models, and the use of adaptive models. This paper does not go into these topics since they go beyond the current focus on reviewing the literature on DL in mining.
This review highlights the reported comparison between the proposed DL method to other methods such as ML and DL of other architecture if available in the collated articles. This should be a common practice when proposing a DL framework especially if the dataset and/or the implementation code is not publicly accessible in order to provide a fair point of reference to compare the propose performance to. Although the DL approaches were shown to be beneficial in comparison, the difference in these task-specific networks and the performance uncertainties in the very different mining environments and methods as well as the challenging data collection conditions make it difficult to predict the performance of a specific DL implementation in other mining conditions.
The future step after DL implementations in the mining research space should be to transfer the technology for practical adoption. This can be done by making DL an element of an automation process/framework whereby sensor data is interpreted online rather than relying on data collection for offline testing. The automation framework could include sensors more than just a stand-alone camera, such as LiDAR, radar, hyperspectral, environmental/weather sensors and encoders. The automation process should include a sensor interpretation fusion for thorough situational modelling rather than just relying on one sensor and data type for a single task.
One reason why DL is not yet popular in terms of adoption in the mining context could be due to how DL is treated by practitioners as a black box without much understanding of the uncertainties in the model, especially in terms of what computations the model carries out when making a decision. A DL method that incorporates symbolic representation (Yi et al. 2018) enabling a human-level understanding of the network’s inference logic has been proposed in an effort for explainable DL. Understanding the network’s explainability i.e. the rationale of a model’s output, would strengthen trust in DL adoption in the mining and other industries. Trust might also be improved by better mathematical modelling of the bounds and degradation characteristics of a DL model and in relation to the dynamism of its operational context.
In terms of uncertainties, performing a sensitivity analysis should be conducted before deploying DL into a complex environment such as a mining operation. Mining specific datasets with adversarial attacks applied, similar to Barbu et al. (2019), should be established to develop a robust DL model for such disturbances (Ren et al. 2020). A model capable of handling adversarial attacks would be more robust when deployed in the real world. The dataset collected in developing a deep learning model could be just a subset of the full environmental context. Incorporating an adversarial network could handle the uncertainties from the out-of-distribution context to a certain extent.
This work presents a compact comprehensive review of DL implementations in mining processes. The review has considered which DL methods are implemented in mining research to try to automate the solution of various tasks in exploration, extraction and reclamation-related processes. The adoption rate showed a sharp increase over the last 5 years, even with the slow initial start after DL became mainstream within research communities. DL can be useful in the mining industry applications where subjective opinions are used to make decisions including cases where available models are inaccurate or unsuitable given a large amount of available data and long analysis times due to mine specific trends resulting from the extraction sequence overlaid on the geological formation, care is required to apply models and celebrate successes outside of their training domain. However, further investigations are required to understand the relationships between the development and deployment environment as well as to understand how a model works i.e. the rational of the model’s output.
The similarity of DL frameworks implemented for mining tasks led to a focus on the processes that facilitate learning such as data pre-processing, training and validation methods. These complementary processes enable learning of the model specific to the task and enable the understanding of the trained uncertainties and optimum operational conditions.
Compared to processes such as exploration and reclamation, the extraction process accounts for 71% of articles; extraction is specific to the mining application field, whereas the other applications share knowledge domains such as geoscience and geotechnical engineering.
Most articles adopted a CNN designed for 2D image-based processing taking in image data from vision-based sensors such as cameras, microscopes and satellite images. Different types of data such as point clouds, geological data and signal data were converted into image pixels to enable their use as a CNN input. The implementation of other types of networks such as GAN and GNN should be beneficial to mining research, since these networks have been proven to show better performance in similar applications in different industries.
With the increasing number of deep learning implementations in mining research, deep learning methods have the potential for wider adoption in practice on-site. Importantly, the transition of the mining industry to remote control or automated equipment to enhance the safety of the mining environment provides an important opportunity to integrate Deep Learning within the automation pipeline, which includes the interaction and fusion with sensors and IoT devices. The understanding of trained model uncertainties and model inference could better enforce the trust for the mining industry to adopt deep learning methods in the real world.
Open access funding provided by CSIRO Library Services.
